Neural Networks
Contents
1. Linear Model - Perceptron

2. Two Input Model with 1 Neuron
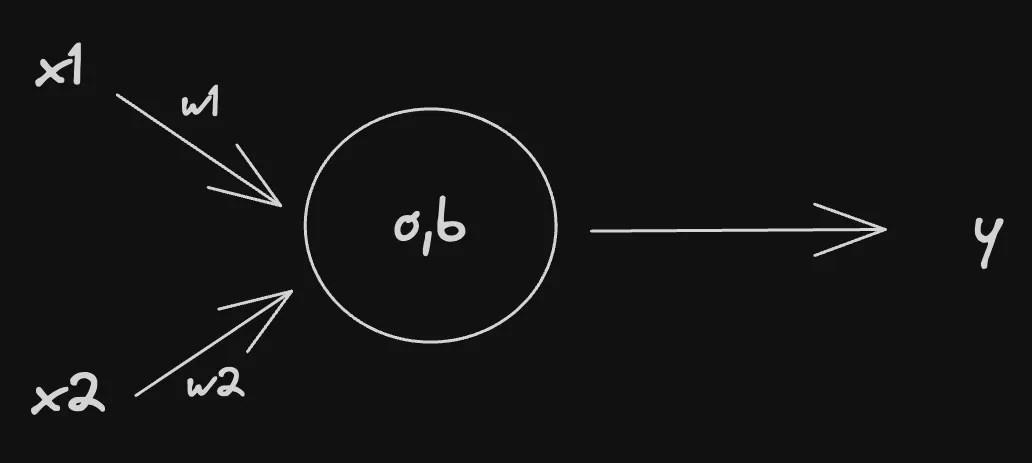
This is then passed through an activation function. This is because the model is not linear and we may need to normalise the values.
3. Two Neuron Model
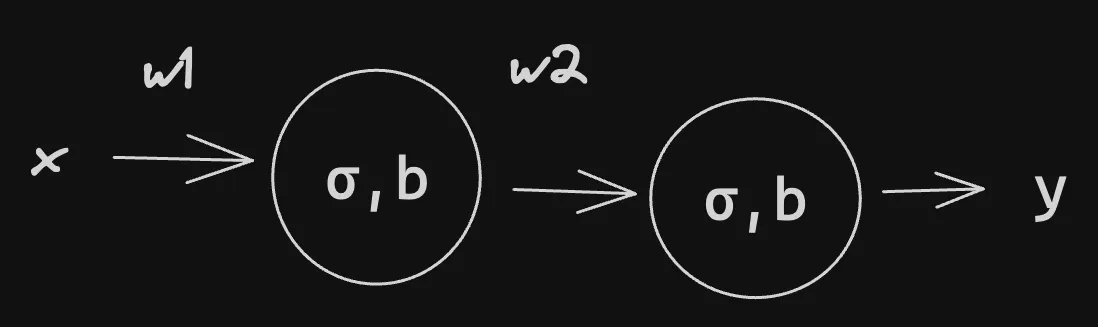
This is the feedforward algorithm. We take the previous layers and feed them into the next. Therefore
Where is the activation for a given layer.
4. Two Layers with Two Neurons Each
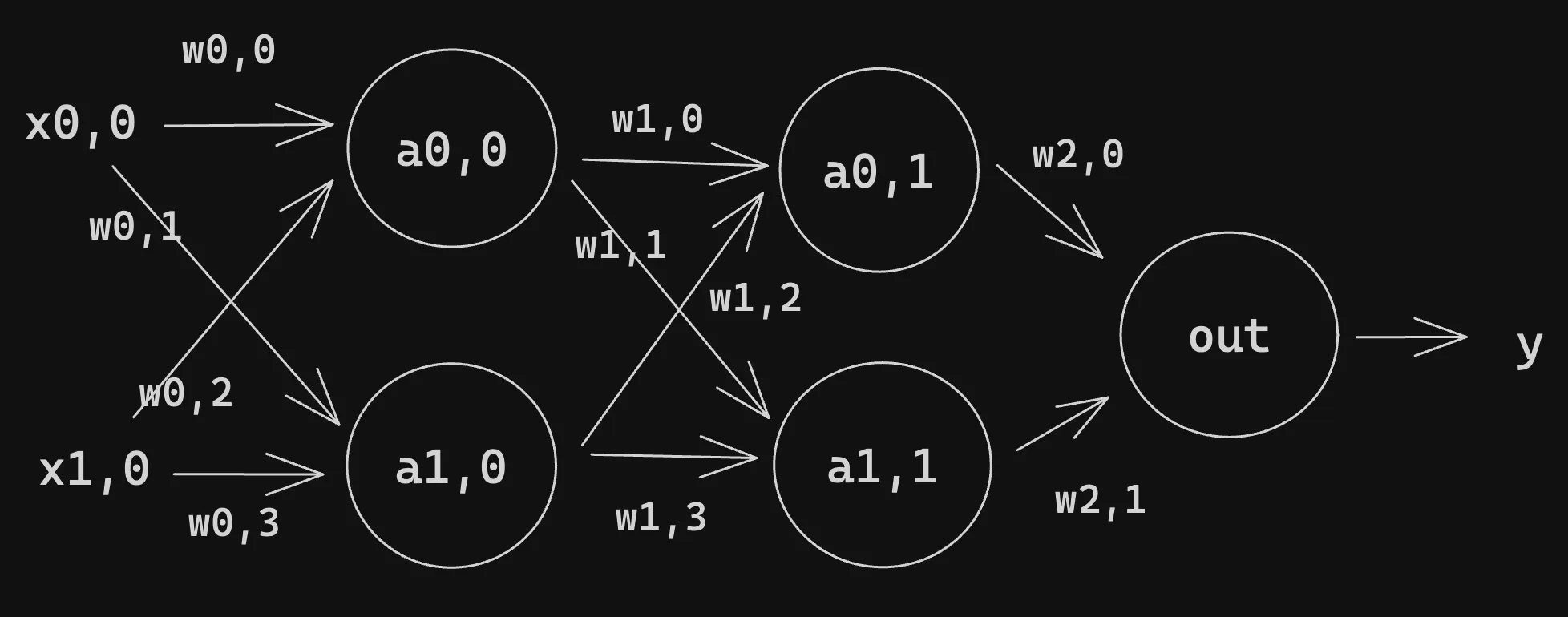
Sometimes we write to represent . We can write this in a more concise manner using vectors and matrices for the transition from one layer to the next:
5. Cost Function
A Cost function measures how well a neural network performs with respect to the given training sample and the expected output. A cost function takes the form:
This function can also possibly be dependent on and for any neuron in layer , since those values are dependent on , , and . In Back Propagation, the cost function is used to compute the error of the output layer, , via This can also be written as a vector via Note that denotes vector product. To be used in back-propagation, a cost function must:
- Be able to be written as an average over cost functions for an individual training example, : This allows us to compute the gradient (w.r.t. and ) for a single training example.
- The cost function must not be dependent on any activation values of a network besides the output values .
5.1 Cost Functions ()
5.1.1 Quadratic Cost
Also known as Mean Squared Error: The gradient of this cost function is the differentiated version:
5.1.2 Cross-Entropy Cost
Also known as Bernoulli Negative Log-Likelihood and Binary Cross-Entropy. Therefore, the gradient is:
Other Cost functions:
- Exponential Cost
- Hellinger Distance
- Kullback-Leiber Divergence
- Generalised Kullback–Leibler divergence
- Itakura–Saito distance
Loss functions help a model determine how wrong a prediction is, which helps the learning algorithm to decide how to minimise it.
- MAE, MSE and RMSE are used for Regression
- Binary Cross Entropy is used for classification.
6. Computing the Gradient
6.1 Gradient Descent
Gradient Decent or Hill-Climbing is the principle by which learning happens. We want to reduce the loss, drive down the loss function, and essentially find the turning point. To do this, we compute the gradient at each point and move in the opposite direction, driving you to the minimum point.
- We find by differentiating the loss function.
- We set a limit on the amount by which a weight can change: the learning rate ().
- The lower the learning rate, the lower the weight change.
6.1.1 Types of Gradient Descent
- Batch Gradient Descent: passing the entire data set and calculating the average loss. This is slow and memory-intensive.
- Mini-Batch Gradient Descent: we define batch sizes, say n, n randomly chosen values are selected, and the cost is computed for those data points.
- Stochastic Gradient Descent: weights are updated after every record; it’s quick and less memory intensive but has high volatility, meaning it may take longer to converge to a minimum.
6.2 Calculate the Gradient
There are many ways to compute a gradient, one example is Finite-Difference or Back Propagation.
6.2.1 Finite-Difference
7. Activation Functions
Activation functions are mathematical operations which are applied to the outputs of individual neurons in a neural network.
- They introduce nonlinearity
- Allow the network to capture intricate patterns.
- Allow it to learn more complex relationships.
- Help generalisation.
- Avoids vanishing and exploding gradients - certain functions like tanh and sigmoid help mitigate vanishing gradients.
- ReLu prevents exploding gradients.
7.1 Types
-
Sigmoid: , ranging from 0 to 1
- Used in the output layer of binary classification
-
Hyperbolic Tangent: inputs range from
-
ReLu: often used but suffers from the dying ReLu problem.
-
Leaky ReLu: allows a small gradient for negative values to solve the dying ReLu issue.
-
Exponential Linear Unit (ELU)
- Combines Leaky ReLu and ReLu to mitigate the dying ReLu issue.
-
Swish Activation: proposed by google gives a smoother behaviour
-
Parametric ReLu (PReLu)
-
Randomised Leaky ReLu (RReLu)
-
Parametric Exponential Linear Unit (PELU)
-
Softmax - muti-class classification
-
Softplus
-
ArcTan
-
Gaussian Error
-
Swish-1 Activation
-
Inverse Square Root Linear Unit (ISRLU)
-
Scaled Exponential Linear Unit (SELU)
-
SoftExponential
-
Bipolar Sigmoid
-
Binary Step Activation
7.2 Usages
1. Sigmoid: Sigmoid activation is well-suited for binary classification problems where you need outputs that resemble probabilities. It squashes input values into the range between 0 and 1, making it ideal for problems with two distinct classes.
2. Tanh (Hyperbolic Tangent): Tanh is an excellent choice for hidden layers, especially when your input data is centred around zero (mean-zero data). It maps input values to the range [-1, 1], which helps mitigate the vanishing gradient problem and is often preferred in recurrent neural networks (RNNs).
3. ReLU (Rectified Linear Unit): ReLU is a widely used activation function and serves as a good default choice for most situations. It introduces sparsity by setting negative values to zero, making it computationally efficient. However, it may lead to dead neurons during training, so it’s crucial to monitor its performance.
4. Leaky ReLU: Leaky ReLU is a variant of ReLU and is employed when the standard ReLU causes neurons to become inactive. It allows a small gradient for negative values, preventing the issue of dead neurons. It’s a recommended alternative to standard ReLU.
5. ELU (Exponential Linear Unit): ELU is valuable when you want the network to capture both positive and negative values within the hidden layers. It addresses the dying ReLU problem and can lead to faster convergence during training.
6. Swish: Swish is an activation function worth experimenting with, as it combines the computational efficiency of ReLU with a smoother, non-monotonic behavior. It has shown potential performance improvements in some architectures.
7. PReLU (Parametric ReLU): PReLU extends Leaky ReLU by allowing each neuron to learn its optimal alpha parameter. This can be beneficial when you want the network to adapt its activation function during training.
8. RReLU (Randomised Leaky ReLU): RReLU introduces randomness as a form of regularisation during training. It can help prevent overfitting and enhance the network’s generalisation ability.
9. PELU (Parametric Exponential Linear Unit): PELU extends ELU by enabling neurons to learn their alpha parameter. This flexibility can be advantageous in various scenarios, allowing the network to adapt to the data.
10. Softmax: Softmax activation is essential for multi-class classification problems in the output layer. It transforms a vector of real numbers into a probability distribution over multiple classes, enabling the network to make class predictions.
11. Softplus: Softplus is a smooth approximation of ReLU and can be helpful when you need a smooth activation function with continuous and differentiable derivatives.
12. ArcTan: ArcTan squashes input values to a limited range between -π/2 and π/2. It can be suitable for specific applications where you must restrict the output within this range.
13. GELU (Gaussian Error Linear Unit): GELU is popular in transformer models and combines a smooth function with Gaussian noise, potentially leading to improved model performance.
14. Swish-1: Swish-1 is a variant of Swish with a division operation. It offers a different activation profile compared to standard Swish and is worth considering in experimentation.
15. ISRLU (Inverse Square Root Linear Unit): ISRLU is a smooth alternative to ReLU that can be helpful when maintaining smooth gradients throughout the network.
16. SELU (Scaled Exponential Linear Unit): SELU encourages automatic activation normalisation and can lead to better training performance, especially in deep neural networks.
17. SoftExponential: SoftExponential introduces nonlinearity with a learnable parameter, allowing the network to adapt to specific data distributions.
18. Bipolar Sigmoid: Bipolar Sigmoid maps inputs to the range between -1 and 1, which can be beneficial when you want to model data with positive and negative values.
19. Binary Step: Binary Step is the simplest activation function, providing binary outputs based on a specified threshold. It’s suitable for binary decision problems.
8. Chain Rule and Partial Derivatives
The chain rule is used to differentiate complex functions.
More Generally:
For example:
8.1 Partial Derivatives
Used in multivariable calculus
First, we treated y as a constant and then x.
9. Back Propagation
Backpropagation repeatedly adjusts the weights of the connections in the network so as to minimise a measure of the difference between the actual output vector of the net and the desired output vector.
The Gradient of a function is a vector of partial derivatives:
- The derivative of a function C measures the sensitivity to a change in the function value (output value) with respect to a change in its argument x (input value). In other words, the derivative tells us the direction C is going.
- The gradient shows how much the parameter x needs to change (in the positive or negative direction) to minimise C For a single weight on layer l ( the gradient is:
This uses the local gradient
9.1 Derivatives of Activation Functions
Sigmoid
10. Optimisation
10.1 Stochastic Gradient Descent
The issue with gradient descent is that it is very computation-heavy.
- We need to compute the derivative with respect to each feature.
- So, with 10,000 data points and 10 features, we are doing this 100,000 times.
- This makes it very slow for large datasets. Stochastic Gradient Descent is a random gradient descent:
- We randomly pick a data point from the whole dataset at each iteration.
- This reduces the computations needed.
Mini-Batch
In Mini-Batch, instead of looking at one data point, we sample a small number of data points.
10.2 Learning Rate
- Learning Rate influences the step size or how the model changes in response to error.
- Too small of an LR could lead to it getting stuck, and large values could lead to training being too fast and thus unstable (converging too quickly).
- The learning rate tends to be in the range of
- Controls how quickly it adapts.
10.2.1 Learning Rate Decay
With learning rate decay, the learning rate is calculated at each update (e.g. end of each mini-batch) as follows: Where lrate is the learning rate for the current epoch, initial_lrate is the learning rate specified as an argument to SGD, decay is the decay rate which is greater than zero and iteration is the current update number.
10.2.2 Learning Rate Scheduler
A learning rate scheduler is a method that adjusts the learning rate during the training process, often lowering it as the training progresses. There are several schedulers for example:
- Step Decay
- Exponential Decay
- Cosine Annealing
10.2.3 Adaptive Learning Rate
Different Methods exist that adapt the learning rate to the problem.
- AdaGrad
- Adam
- RMSProp
10.3 Momentum
Momentum can smooth the progression of the learning algorithm that, in turn, can accelerate the training process.
- It is common to use momentum values close to 1.0, such as 0.9 and 0.99.
- Since SGD converges randomly, momentum is used to remove this random aspect.
- Using all previous updates, the momentum at time ‘t’ is calculated, giving more weight to the latest updates compared to the previous update in order to speed convergence
- Momentum makes SGD faster.
Where
- : Weights at iteration
- : Learning rate
- : Gradient of the loss function with respect to weights
- : Velocity (tracks the moving average of gradients)
- : Momentum coefficient (commonly ) Why?
- Faster Convergence:
- Momentum reduces oscillations along steep gradients (e.g., in narrow valleys) by dampening the effect of gradients that alternate in direction.
- It helps the optimiser gain speed along flatter dimensions of the loss surface.
- Escape from Local Minima:
- By incorporating past updates, momentum can help the optimiser “push through” small local minima or saddle points.
- Stability:
- Momentum smooths the optimisation path, leading to a more stable and predictable learning process.
11. Data
11.1 Data Shuffling
It is useful to shuffle the training data during training.
- Preventing Bias: Without shuffling, the model might learn patterns based on the order of the data, leading to biased training and potentially poor generalisation to unseen data.
- Randomness in Batch Selection: When training in mini-batches, shuffling ensures that each batch contains a diverse set of samples from the dataset. This randomness helps the model learn more effectively and prevents it from memorising specific patterns within a batch.
- Improving Generalisation: Shuffling the data helps to ensure that the model generalises well to unseen data by exposing it to a variety of samples during training. This can lead to better performance on validation and test datasets.
- Breaking Patterns: In some cases, the dataset might have inherent patterns based on the order of samples (e.g., temporal or spatial patterns). Shuffling disrupts these patterns, forcing the model to learn more robust features.
- Avoiding Overfitting: Shuffling helps to mitigate overfitting by preventing the model from memorising the specific characteristics of the training data, which may not generalise well to new data.
11.2 Data Batching
A batch defines how many samples to work through before making any updates to parameters. This is useful for:
- computational efficiency
- paralellisability
- Helps with memory management
- Gradient Smoothing: By averaging gradients across a batch, training becomes less noisy
- Smaller batches create a regularisation effect.